
刚刚! 华为宣布首次开源大模型, 百度也同日开源了
发布日期:2025-07-05 20:28 点击次数:125

6月30日,华为正式宣布开源盘古70亿参数的稠密模型、盘古Pro MoE 720亿参数的混合专家模型和基于昇腾的模型推理技术。据悉,这是华为首次开源大模型。
华为称,此举是华为践行昇腾生态战略的又一关键举措,推动大模型技术的研究与创新发展,加速推进人工智能在千行百业的应用与价值创造。
其中,盘古Pro MoE 72B模型权重、基础推理代码,以及基于昇腾的超大规模MoE模型推理代码,已正式上线开源平台。盘古7B相关模型权重与推理代码将于近期上线开源平台。
华为诚邀全球开发者、企业伙伴及研究人员下载使用。
华为公布的开源项目
根据华为公布的开源链接来看,包括八个项目:
地址:https://gitcode.com/ascend-tribe
1、盘古 Pro MoE (72B-A16B):昇腾原生的分组混合专家模型;
2、昇腾超大规模MoE模型训练系统技术;
3、昇腾盘古推理系统技术;
4、昇腾超大规模MoE模型推理部署技术;
5、昇腾AI算力集群基础设施技术;
6、【模型权重】盘古Pro MoE (72B-A16B):昇腾原生的分组混合专家模型
7、Pangu Ultra MoE 模型架构与训练方法;
8、盘古 Embedded (7B):灵活切换快慢思考的高效7B模型
以《盘古Pro MoE (72B-A16B):昇腾原生的分组混合专家模型》为例:
据介绍,混合专家模型(MoE)在大语言模型(LLMs)中逐渐兴起,该架构能够以较低计算成本支持更大规模的参数,从而获得更强的表达能力。然而,在实际部署中,不同专家的激活频率存在严重的不均衡问题,一部分专家被过度调用,而其他专家则长期闲置,导致系统效率低下。
为此,华为盘古团队提出了新型的分组混合专家模型(Mixture of Grouped Experts, MoGE),它在专家选择阶段对专家进行分组,并约束token 在每个组内激活等量专家,从而实现专家负载均衡,显著提升模型在昇腾平台的部署效率。基于MoGE 架构,华为团队构建了总参数量720亿、激活参数量160亿的盘古Pro MoE模型,并针对昇腾300I Duo 和800I A2平台进行系统优化。
盘古Pro MoE在昇腾 800I A2上实现了单卡1148 tokens/s 的推理吞吐性能,并可进一步通过投机加速等技术提升至1528 tokens/s,显著优于同等规模的320亿和720亿参数的稠密模型;在昇腾 300I Duo推理服务器上,华为也实现了极具性价比的模型推理方案。研究表明,昇腾 NPU 能够支持盘古 Pro MoE 的大规模并行训练,使其成为总参数量在千亿以下的领先模型。
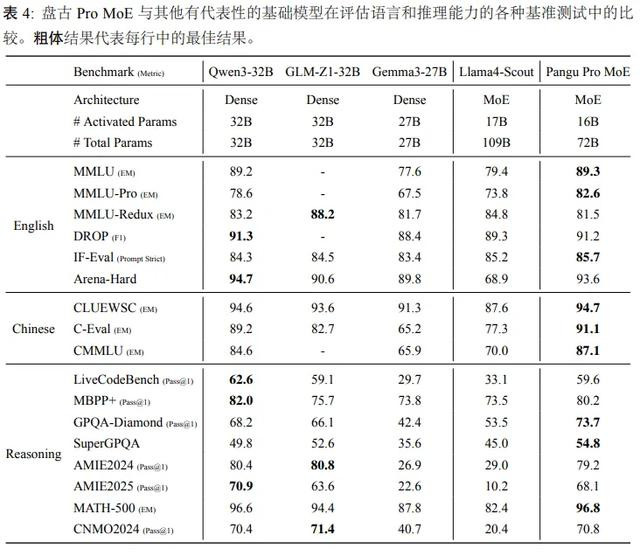
根据其评测结果显示:
在英文基准中,盘古Pro MoE在MMLU-PRO上以显著优势超越当前主流的稠密模型(包括 Qwen3-32B、GLM-Z1-32B 和 Gemma3-27B)及 MoE 架构的 Llama4-Scout 模型,创下新的性能标杆。在阅读理解领域,盘古 Pro MoE 于 DROP 基准测试中获得 91.2 的优异成绩,与当前最优的 Qwen3-32B 模型(91.3)基本持平,充分验证其具备与前沿模型相当的英文文本理解与推理能力。
在中文领域评估中,盘古Pro MoE 展现出专业化的语言理解优势。具体而言,在知识密集型评测 C-Eval(EM)中,盘古 Pro MoE 以 91.1 的卓越成绩超越 Qwen3-32B(89.2)等现有百亿参数量级最优模型。针对中文常识推理任务,盘古 Pro MoE 在 CLUEWSC(EM)基准上取得 94.7 的高分,较 Qwen3-32B(94.6)实现微幅提升,并明显领先于 Gemma3-27B(91.3)等其他对比模型。实验结果表明,盘古 Pro MoE 在中文语义理解与常识推理方面达到行业领先水平。
华为盘古大模型
盘古大模型,是华为旗下的盘古系列AI大模型,包括NLP大模型、CV大模型、科学计算大模型。其名称寓意“开天辟地”,象征着华为在人工智能基础研究和行业应用上的突破性探索。
在最近的6月20日,华为开发者大会2025(HDC 2025)上,华为云重磅发布盘古大模型5.5版本,包括盘古预测大模型,盘古多模态大模型,盘古自然语言大模型,盘古视觉大模型,盘古科学计算大模型。

据介绍,盘古自然语言处理NLP大模型:全新的718B 深度思考模型是一个由256个专家组成的MoE大模型,在知识推理、工具调用、数学等领域大幅增强,处于业界第一梯队。盘古大模型基于昇腾云的全栈软硬件训练,标志着基于昇腾可以打造出世界一流大模型。
会上,华为常务董事、华为云计算CEO张平安宣布,发布盘古医学、金融、政务、工业、汽车五个具备深度思考能力的行业自然语言大模型,加速行业智能化,并将在6月底正式上线。
比如,全新发布基于盘古多模态大模型的世界模型,可以为智能驾驶、具身智能机器人的训练。同时,基于盘古大模型的多模态能力及思维能力,华为正式发布CloudRobo具身智能平台。据悉,该平台整合了数据合成、数据标注、模型开发、仿真验证、云边协同部署以及安全监管等端到端能力,提供具身多模态生成大模型、具身规划大模型、具身执行大模型三大核心模型,加速具身智能创新。

华为称,在过去的一年中,盘古大模型持续深耕行业,已在30多个行业、500多个场景中落地,在政务、金融、制造、医疗、煤矿、钢铁、铁路、自动驾驶、气象等领域发挥巨大价值,重塑千行万业。
值得注意的是,就在同日,6月30日,百度也正式开源了——文心大模型4.5系列模型,涵盖47B、3B激活参数的混合专家(MoE)模型,与0.3B参数的稠密型模型等10款模型,并实现预训练权重和推理代码的完全开源。Hugging Face:https://huggingface.co/baidu/models
目前,文心大模型4.5开源系列已可在飞桨星河社区、HuggingFace等平台下载部署使用,同时开源模型API服务也可在百度智能云千帆大模型平台使用。